
Graph, Tree, Hash Tables, Binary Tree (B-Tree)
자료구조 정리 2편 Binary Tree
Tree
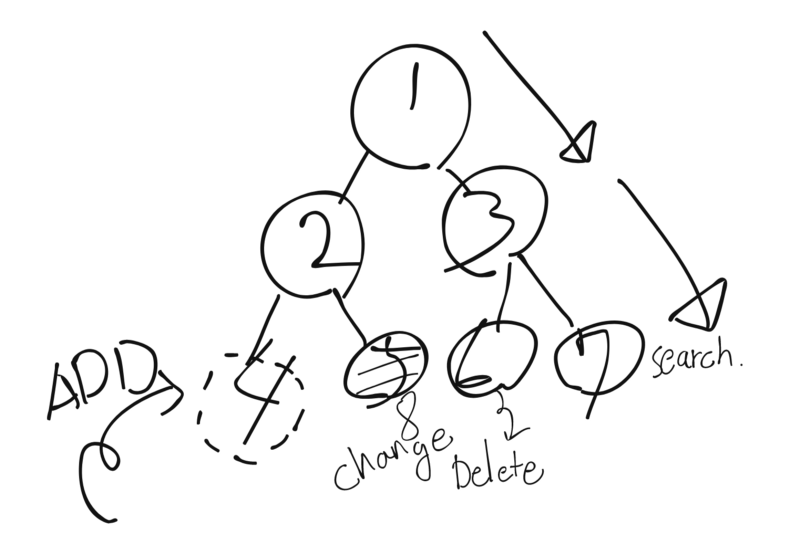
- 1편에서 알아본 자료구조는 각자 특징이 있었지만 모두 선형적구조를 가지고 있었다.
- 2편은 그렇지 않은 자료구조의 모임이며 Tree는 그중 Root를 가지고 하위노드를 거느린다는 특징을 가진다.
- Tree를 규정하는 가장 중요한 원칙 ‘각 노드가 하나의 부모만을 가진다’
- 하위노드를 몇 개를 가지는지, 하위노드의 갯수가 불완전해도 되는지, 깊이의 불균등, 데이터를 어떤 순으로 담을지에 따라 여러종류의 Tree를 만들 수 있다.
- 위아래가 있는 위계적 구조는 관료제도를 떠오르게 하는데 인간의 인지구조에 친화적인 구조이다. (DOM도 이러한 구조로 구성되어 있다)
-
선형적 구조보다 복잡한 구조인 만큼 노드들이 위치에 따라 호칭을 가진다.객체지향 프로그래밍이나 여러 OS의 파일시스템도 Tree의 모양새이기 때문에 익숙한 단어들이 존재한다. (Root, Child, Parent)
Brother(Sibling Node): 어떤 노드의 같은 레벨에 있는 노드Leaf Node: 자식 노드가 존재하지 않는 끝단 노드Branch Node: 자식 노드가 있지만 Root가 아닌 중간노드Edge: 노드간의 관계를 나타냄- Tree를 관리하기 위해서
Add, Search, Delete, Change등의 메서드가 필요
class Node {
data;
leftNode;
rightNode;
show() {
return this.data;
}
}
class Tree {
root;
setRoot(node){
this.root = node
}
getRoot(){
return root;
}
//재귀로 트리를 출력
inOrder(node){
if (!(node === null)){
this.inOrder(node.left);
console.log(node.show());
this.inOrder(node.left);
}
find(data) {
let currentNode = this.root;
//이진트리는 data와 currentNode.data와 비교하여 왼쪽 오른쪽을 선택하여 탐색을 할 수 있다.
}
remove(data) {
//자식이 있는 경우와 없는 경우를 나눠처리
}
makeNode(data, leftNode, rightNode){
}
}
B-Tree
- 이진 트리는 각각의 노드가 최대 두 개의 자식 노드를 가지는 트리 자료구조를 말함. 더 많은 자식을 가지면 B트리. B-Tree는 시간복잡도면에선 뛰어남. 데이터베이스에서 많이 사용.
Graph
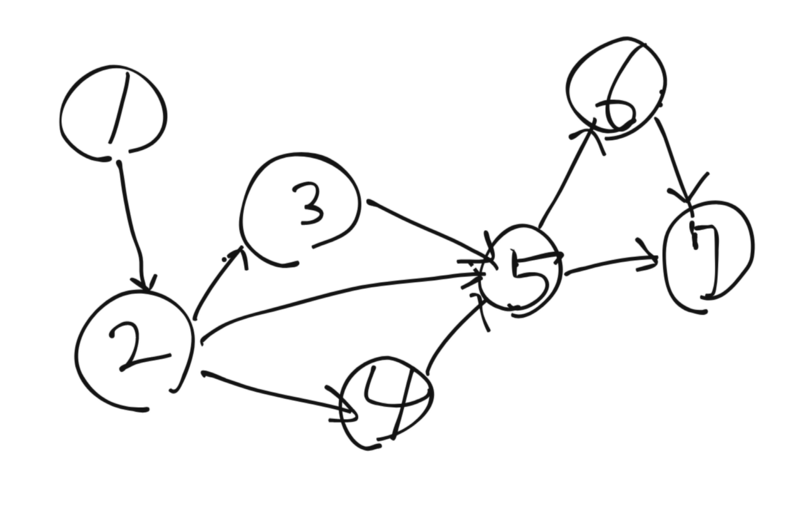
- Graph는 부모를 가지고 자녀를 가지는 면에서 Tree와 비슷하지만 Tree에 있는 몇 가지 제약이 없는 사실상 Tree의 상위호환격 자료구조이다. 몇 개의 자식노드(인접노드)를 가지는지 제약도 없고 root도 없기 때문이다.
- Directed Graph, Undirected Graph로 나뉜다. (Tree는 Directed)
- 트리구조가 질서정연한 관료제도를 떠올리게 한다면 Graph는 현실에 있는 복합적인 구조를 떠올리게 한다. 다차원적으로 얽힌 인간관계, 골목길과 고속도로, 고가도로 등이 복합적으로 존재하는 도로망 이러한 현실은 Graph로 구현하기에 적합하다.
- 다른 노드에서 오는 엣지의 개수를 In-degree 다른 노드로 가는 엣지의 개수를 Out-degree라 한다. (방향이 있는 Graph에서 표현되는 방식) 트리는 이 degree의 갯수가 트리의 규칙에 예속되어 있었지만 Graph는 제약이 없다.
var Graph = function () {
function Node(key){
//노드의 생성자. 연결된 edge, direct 등 노드의 동작을 규약하는 프로퍼티를 작성한다.
//key는 노드의 관계를 규정하는 매개변수
}
function Edge(data, dest, capacity){
//엣지의 생성자. 다음 노드가 담아야할 정보를 담은 프로퍼티를 작성
}
function Graph() {
//Graph 전반의 특성을 규정하는 생성자. (갯수, direct인 경우 첫째 노드)
}
//노드 및 엣지의 삭제 및
Graph.prototype.insertNode = function (key) {}
Graph.prototype.deleteNode = function (key) {}
Graph.prototype.insertEdge = function (data, fromKey, toKey, capacity) {}
Graph.prototype.deleteEdge = function (fromkey, toKey) {}
}
Hash table
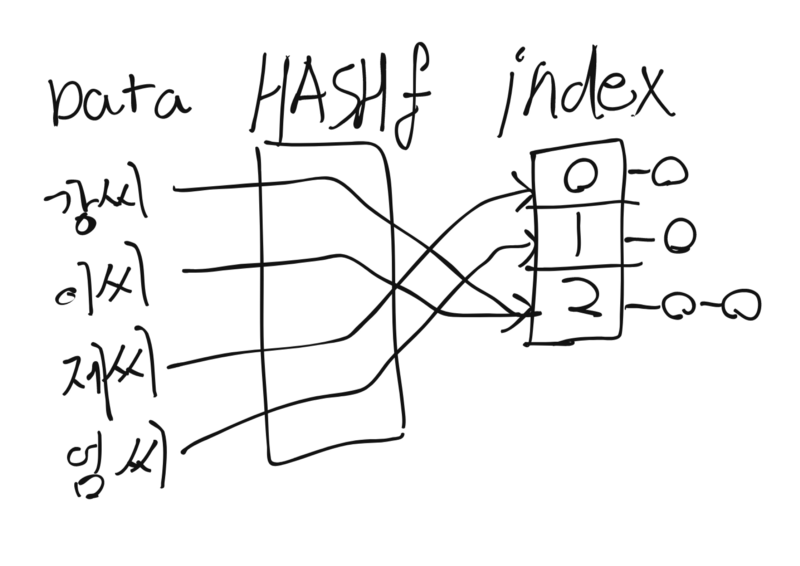
Separate chaining 방식 해쉬테이블
- 배열은 빠른 탐색속도를 보장한다. 하지만 배열에 직접 데이터를 담으면 비용이 커진다. Data가 파일 이라면 더욱더 그러하다. 해시테이블은 이런 문제를 해결하기 위한 자료구조이다.
- 데이터를 해시함수에 집어넣어서 배열의 인덱스(버켓)로 활용할 수 있는 값을 얻는다. 그리고 그것을 인덱스의 크기로 나눠 나머지로 인덱스를 결정한다. 특정 인덱스에 몰리면 탐색비용이 증가하기 때문에 모든 인덱스에 골고루 분포되도록 해시함수를 만드는게 중요하다.
- 해수함수가 만들 수 있는 결과값 종류보다 인덱스 사이즈가 작을수록 더 많은 중복이 생기는데 그 때 2차탐색을 처리하는 방식은 인덱스에 Linked List를 할당하는 Separate chaining 아직 사용되지 않은 Hash에 중복되는 값을 넣어버리는 Open addressing
const hash = (string, bucketSize) => {
// 데이터와 size를 기반으로 인덱스를 반환
}
const HashTable = function(){
size = 100;
add(key, value){
index = hash(key, size);
// hash를 호출해서 값을 얻고 해시테이블에 집어넣는다.
}
remove(key){
index = hash(key, size);
// key를 기준으로 해시테이블을 탐색해서 값을 삭제한다.
}
lookup(key){
index = hash(key, size);
// key를 기준으로 해시테이블을 탐색하여 값을 반환.
return value
}
}
const testHashTable = new HashTable();
testHashTable.add('Kang', 'Taehun은 노력중.... 그의 일생을 담은 엄청난 데이터');
testHashTable.lookup('Kang'));
Leave a comment